Number of topics
The most important parameter for building a topic model is the number of topics. Too low of a number will result in overly broad topics or merges between unrelated topics, while too high of a number can create non-semantic splits within topics and hide larger trends. To observe these differences, we built models of 10 and 50 topics on the works of William Shakespeare.
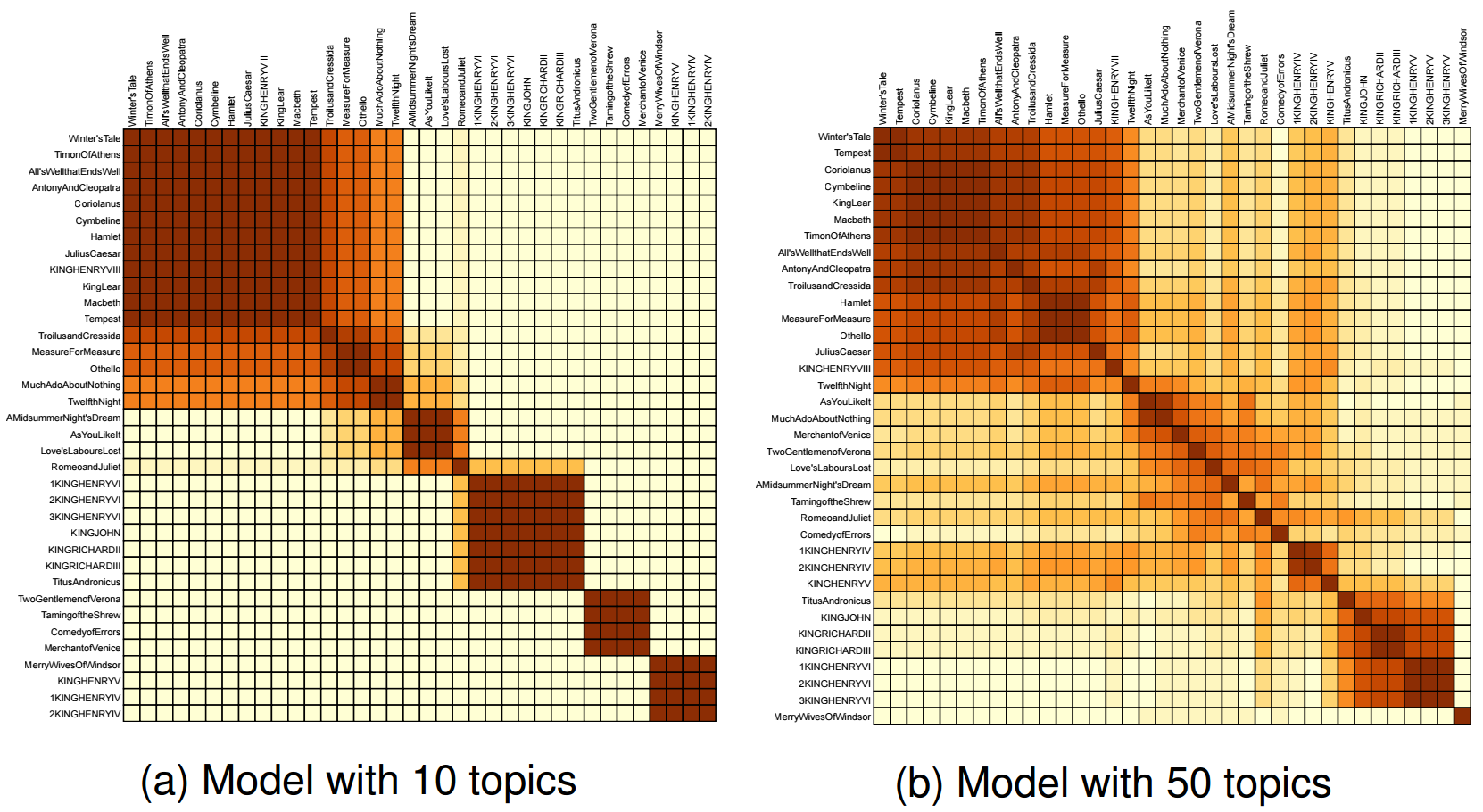
The primary difference we saw between the two models is how they cluster. Above is a heatmap of the consistency of clustering across 20 runs of k-means upon the 10-topic model. We can see that with the minor exception of the cluster in the direct center (and in particular, Romeo and Juliet), the groups being formed are quite consistent. The 50-topic model, on the other hand, exhibits much less consistency. Many documents appear with almost all of the others in a cluster in at least one of the runs. For a user hoping to explore the differences between these groups, the 10-topic model may give them cleaner distinctions to investigate.